
HTTP Status Code crawling in Bash
Senior Software Engineer & Tech/Team Lead @ WeRoad
On the last day I had to rewrite the whole sitemap of a site to boost its performance and I needed to check if the generated URLs were responding 2xx and not another HTTP Status Code, so I wrote a little script in Bash.
Why Bash and not another language? Since I had to use curl -I I thought it was simpler in Bash and it is more portable; let's see the result.
The first thing is to loop line by line a file, which will contain our URLs and I found on StackOverflow this while loop to achieve it. It will take the filename from the args when you run the script (done < "$1").
#!/bin/bash
while IFS='' read -r line || [[ -n "$line" ]]; do
echo "[${i}] Doing $line"
done < "$1"
At this time it just prints each line, so we need to capture the output of curl to get the HTTP Code.
#!/bin/bash
while IFS='' read -r line || [[ -n "$line" ]]; do
echo "[${i}] Doing $line"
statusCode=$(curl -s -o /dev/null -I -w "%{http_code}" $line)
done < "$1"
Let's explain a bit of the curl arguments:
-shides the progress of the "call";-o /dev/nullhides the body of the results;-Ifetches the headers only (HEADmethod);-w "%{http_code}"writes the HTTP Status Code tostdoutafter exit.
Now the most important check: is the status code a valid one? Right after the declaration of statusCode, let's add this:
if [[ "$statusCode" != 2* ]]; then
echo "Code: $statusCode"
fi
We are telling the script: if the content of statusCode doesn't start with "2" (200, 201, 204 and so on), print the error.
The script is finished and its final results will be this:
#!/bin/bash
while IFS='' read -r line || [[ -n "$line" ]]; do
echo "[${i}] Doing $line"
statusCode=$(curl -s -o /dev/null -I -w "%{http_code}" $line)
if [[ "$statusCode" != 2* ]]; then
echo "Code: $statusCode"
fi
done < "$1"
Let's try it. Create a file called urls.txt with this content and save it in the same directory of our script (status_code.sh):
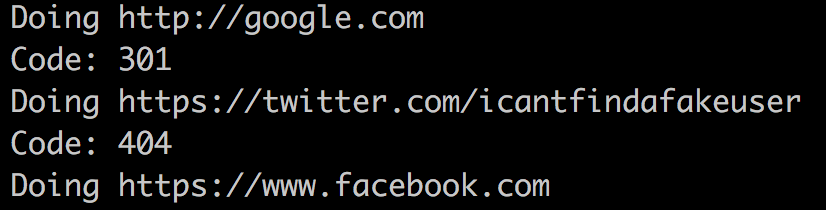
http://google.com
https://twitter.com/icantfindafakeuser
https://www.facebook.com
Now run it with bash status_code.sh urls.txt and the output will look like this:
Improvements
The script works pretty well, but if you have a lot of URLs it could be hard to retrieve all the errors, so we can store them in an array and print them at the end of the script.
We will add an empty array at the beginning of the file and then push the "wrong" URL to it when it doesn't return a 2xx status code.
#!/bin/bash
# Empty array
errors=()
while IFS='' read -r line || [[ -n "$line" ]]; do
echo "Doing $line"
statusCode=$(curl -s -o /dev/null -I -w "%{http_code}" $line)
if [[ "$statusCode" != 2* ]]; then
echo "Code: $statusCode"
errors+=("[${statusCode}] ${line}")
fi
sleep 2
done < "$1"
Now, after the while loop, we are going to print the number of errors and their content.
Note: I have added a sleep 2 to create a delay of 2 seconds between each curl.
#!/bin/bash
# Empty array
errors=()
while IFS='' read -r line || [[ -n "$line" ]]; do
echo "Doing $line"
statusCode=$(curl -s -o /dev/null -I -w "%{http_code}" $line)
if [[ "$statusCode" != 2* ]]; then
echo "Code: $statusCode"
errors+=("[${statusCode}] ${line}")
fi
sleep 2
done < "$1"
echo "---------------"
errorsCount=${#errors[@]}
echo "Found $errorsCount errors."
if (( $errorsCount > 0 )); then
printf '%s\n' "${errors[@]}"
fi
The printf in the last condition will print the items in our array one-per-line, otherwise, they would be all in the same line, hard to read.
If we run again our script, always with bash status_code.sh urls.txt, the new output will be the following:

Of course, it there won't be errors, the array won't be printed.
The final touch: line offset
The last improvement we can make is to add the possibility to choose the offset of the script, so we can specify from which line we want to start. This is useful if we have a lot of URLs and our script dies or there is some unexpected error.
We will create a i variable incremented in each iteration of the loop. If, when we run the script, there is a second (actually third, the index starts from 0) argument ("$2"), we will check if our i is less than it and, in case, we will skip the current URL.
#!/bin/bash
# Empty array
errors=()
i=0
while IFS='' read -r line || [[ -n "$line" ]]; do
# Increment the variable
((i++))
# Skip if offset if specified and current index less than it
if [[ "$2" && $i -lt "$2" ]]; then
continue
fi
echo "[${i}] Doing $line"
statusCode=$(curl -s -o /dev/null -I -w "%{http_code}" $line)
if [[ "$statusCode" != 2* ]]; then
echo "Code: $statusCode"
errors+=("[${statusCode}] ${line}")
fi
sleep 2
done < "$1"
echo "---------------"
errorsCount=${#errors[@]}
echo "Found $errorsCount errors."
if (( $errorsCount > 0 )); then
printf '%s\n' "${errors[@]}"
fi
We added also a "tracker" in the line printing to know the current line index. Let's try it out: for example, we want to start from the second line: bash status_code.sh urls.txt 2.

This is it, hoping it helped.




